Ist Step: Decide the training data set
To prepare the training data for Bangla characters I considered the followings:
- Basic characters (vowel + consonant) / units, numerals and symbols
- consonant + vowel modifiers
- consonant + consonant modifiers
- combined consonants (compound character)
- compound character + vowel modifiers
- compound character + consonant modifiers
The total number of training unit is 3200.
2nd Step: Prepare training data images
We typed all the combinations and take print out of the documents (13 page). Next we scan the pages and manually preprocessed the pages which includes skew correction. We choose the most popular font (SutonnyMJ) that have been widely used for a long time to print Bangla documents as maximum documents that we are targetting to OCRized is written in that font. The font is non unicode which is the only problem because it cannot be used for transcription. So, we used unicode font (Solaimanlipi) to prepare the transcription. An example is shown in figure-1.


Figure-1 : Example of training image files
3rd Step: Prepare training data files using tesseractNext we prepare box files (*.box), training files (*.tr), clustered files (*.inttemp, *.normproto and *.pffmtable) and character set file (*.unicharset) appropriate instructions.
To create box file we didn't rely on the box file creation of process of tesseract as we find that it failed in many times and also it generates inappropriate box information for Bangla characters. So, used our own box file creation lua script which successfully create box file with appropriate transcription. Still we have to handle several character images manually. We might avoid the manual process if we chose mix document like real case in a document image . Another important point here is that we have to eliminate few units during training because of the presence of a certain amount of gap between the core character and its modifier in those character images. An example of such units are given in figure-2.

Figure-2 : Example of image units which failed in tesseract training
An example of the error report is as follows:
hasnat@hasnat-desktop:~$ tesseract 13.tif junk nobatch box.train
Tesseract Open Source OCR Engine
APPLY_BOXES: boxfile 2/1/সুঁ ((19,1388),(67,1468)): FAILURE! box overlaps no blobs or blobs in multiple rows
4th Step: Prepare language specific data files
To prepare language specific dictionary data file (freq_dawg and word_dawg) we choose a word list of 180K words and frequent word list of 30K words. The third file user_words is empty. We add only two rules in the DangAmbigs file.
We followed these four stpes to prepare complete training data.
We followed these four stpes to prepare complete training data.
Testing:
As we are using ocropus-tesseract so we get the facility of getting preprocessed image just before segmentation. We applied our own segmentation algorithm to segment the words into characters. Figure-3 shows an example of the training image and figure-4 shows the output of our segmenter. This segmented image is then passed to the tesseract recognizer to obtain the output text.

Figure-3 : Test Image
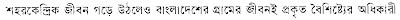
Figure-4 : Segmentation result

Figure-4 : Segmentation result
For the test image we got following unicode output. শহরেকন্দ্রিধী জীঁবন গেড় উঠলেও বাংল্লদেশের গ্রামের র্জীবনই প্রকৃত বৈশিষ্টে্যযুঁ অধিকারী.
My feedback:
My feedback:
Definitely I am not satisfied with this output. I had the initial expectation that after using the dictionary files of large word list we would be able to get more accurate result than the past approach while we used a word list of only 70 basic characters.
Next TODO:
I plan to do the following tasks to improve the efficiency:
1. Train each unit with at least 10 samples. (Right now, number of sample per unit = 1)
2. Train each unit with variations.
3. Collect training units from testing documents which is a lenthy process.
2 comments:
I am training tesseract to recognize English text with romanized Sanskrit words - so I need to add 20-something new accented roman characters to the basic alphabet. The results I get are somewhat OK but it would seem that adding a sanskrit word to the list will not improve its recognition rate.
It feels like the dictionary files are just window dressing. Is that your experience too?
Yes, you are right. The dictionary files is not working for Indic languages. I ave already discussed about this in the tesseract ocr group. Nice to know about your experiment. Wish to hear more from you.
Post a Comment